A Web Crawler is a program that navigates the Web and finds new or updated pages for indexing. The Crawler starts with seed websites or a wide range of popular URLs (also known as the frontier) and searches in depth and width for hyperlinks to extract.
A Web Crawler must be kind and robust. Kindness for a Crawler means that it respects the rules set by the robots.txt and avoids visiting a website too often. Robustness refers to the ability to avoid spider traps and other malicious behavior. Other good attributes for a Web Crawler is distributivity amongst multiple distributed machines, expandability, continuity and ability to prioritize based on page quality.
1. Steps to create web crawler
The basic steps to write a Web Crawler are:
- Pick a URL from the frontier
- Fetch the HTML code
- Parse the HTML to extract links to other URLs
- Check if you have already crawled the URLs and/or if you have seen the same content before
- If not add it to the index
- For each extracted URL
- Confirm that it agrees to be checked (robots.txt, crawling frequency)
Truth be told, developing and maintaining one Web Crawler across all pages on the internet is… Difficult if not impossible, considering that there are over 1 billion websites online right now. If you are reading this article, chances are you are not looking for a guide to create a Web Crawler but a Web Scraper. Why is the article called ‘Basic Web Crawler’ then? Well… Because it’s catchy… Really! Few people know the difference between crawlers and scrapers so we all tend to use the word “crawling” for everything, even for offline data scraping. Also, because to build a Web Scraper you need a crawl agent too. And finally, because this article intends to inform as well as provide a viable example.
2. The skeleton of a crawler
For HTML parsing we will use jsoup. The examples below were developed using jsoup version 1.10.2.
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
So let’s start with the basic code for a Web Crawler.
package com.mkyong.basicwebcrawler;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.HashSet;
public class BasicWebCrawler {
private HashSet<String> links;
public BasicWebCrawler() {
links = new HashSet<String>();
}
public void getPageLinks(String URL) {
//4. Check if you have already crawled the URLs
//(we are intentionally not checking for duplicate content in this example)
if (!links.contains(URL)) {
try {
//4. (i) If not add it to the index
if (links.add(URL)) {
System.out.println(URL);
}
//2. Fetch the HTML code
Document document = Jsoup.connect(URL).get();
//3. Parse the HTML to extract links to other URLs
Elements linksOnPage = document.select("a[href]");
//5. For each extracted URL... go back to Step 4.
for (Element page : linksOnPage) {
getPageLinks(page.attr("abs:href"));
}
} catch (IOException e) {
System.err.println("For '" + URL + "': " + e.getMessage());
}
}
}
public static void main(String[] args) {
//1. Pick a URL from the frontier
new BasicWebCrawler().getPageLinks("https://mkyong.com/");
}
}
Don’t let this code run for too long. It can take hours without ending.
Sample Output:
https://mkyong.com/
Android Tutorial
Android Tutorial
Java I/O Tutorial
Java I/O Tutorial
Java XML Tutorial
Java XML Tutorial
Java JSON Tutorials
Java JSON Tutorials
Java Regular Expression Tutorial
Java Regular Expression Tutorial
Java JDBC Tutorials
...(+ many more links)
Like we mentioned before, a Web Crawler searches in width and depth for links. If we imagine the links on a web site in a tree-like structure, the root node or level zero would be the link we start with, the next level would be all the links that we found on level zero and so on.
3. Taking crawling depth into account
We will modify the previous example to set depth of link extraction. Notice that the only true difference between this example and the previous is that the recursive getPageLinks() method has an integer argument that represents the depth of the link which is also added as a condition in the if...else statement.
package com.mkyong.depthwebcrawler;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.HashSet;
public class WebCrawlerWithDepth {
private static final int MAX_DEPTH = 2;
private HashSet<String> links;
public WebCrawlerWithDepth() {
links = new HashSet<>();
}
public void getPageLinks(String URL, int depth) {
if ((!links.contains(URL) && (depth < MAX_DEPTH))) {
System.out.println(">> Depth: " + depth + " [" + URL + "]");
try {
links.add(URL);
Document document = Jsoup.connect(URL).get();
Elements linksOnPage = document.select("a[href]");
depth++;
for (Element page : linksOnPage) {
getPageLinks(page.attr("abs:href"), depth);
}
} catch (IOException e) {
System.err.println("For '" + URL + "': " + e.getMessage());
}
}
}
public static void main(String[] args) {
new WebCrawlerWithDepth().getPageLinks("https://mkyong.com/", 0);
}
}
Feel free to run the above code. It only took a few minutes on my laptop with depth set to 2. Please keep in mind, the higher the depth the longer it will take to finish.
Sample Output:
...
>> Depth: 1 [https://docs.gradle.org/current/userguide/userguide.html]
>> Depth: 1 [http://hibernate.org/orm/]
>> Depth: 1 [https://jax-ws.java.net/]
>> Depth: 1 [http://tomcat.apache.org/tomcat-8.0-doc/index.html]
>> Depth: 1 [http://www.javacodegeeks.com/]
For 'http://www.javacodegeeks.com/': HTTP error fetching URL
>> Depth: 1 [http://beust.com/weblog/]
>> Depth: 1 [https://dzone.com]
>> Depth: 1 [https://wordpress.org/]
>> Depth: 1 [http://www.liquidweb.com/?RID=mkyong]
>> Depth: 1 [https://mkyong.com/privacy-policy/]
4. Data Scraping vs. Data Crawling
So far so good for a theoretical approach on the matter. The fact is that you will hardly ever build a generic crawler, and if you want a “real” one, you should use tools that already exist. Most of what the average developer does is an extraction of specific information from specific websites and even though that includes building a Web Crawler, it’s actually called Web Scraping.
There is a very good article by Arpan Jha for PromptCloud on Data Scraping vs. Data Crawling which personally helped me a lot to understand this distinction and I would suggest reading it.
To summarize it with a table taken from this article:
| Data Scraping | Data Crawling |
|---|---|
| Involves extracting data from various sources including the web | Refers to downloading pages from the web |
| Can be done at any scale | Mostly done at a large scale |
| Deduplication is not necessarily a part | Deduplication is an essential part |
| Needs crawl agent and parser | Needs only crawl agent |
Time to move out of theory and into a viable example, as promised in the intro. Let’s imagine a scenario in which we want to get all the URLs for articles that relate to Java 8 from mkyong.com. Our goal is to retrieve that information in the shortest time possible and thus avoid crawling through the whole website. Besides, this approach will not only waste the server’s resources, but our time as well.
5. Case Study – Extract all articles for ‘Java 8’ on mkyong.com
5.1 First thing we should do is look at the code of the website. Taking a quick look at mkyong.com we can easily notice the paging at the front page and that it follows a /page/xx pattern for each page.
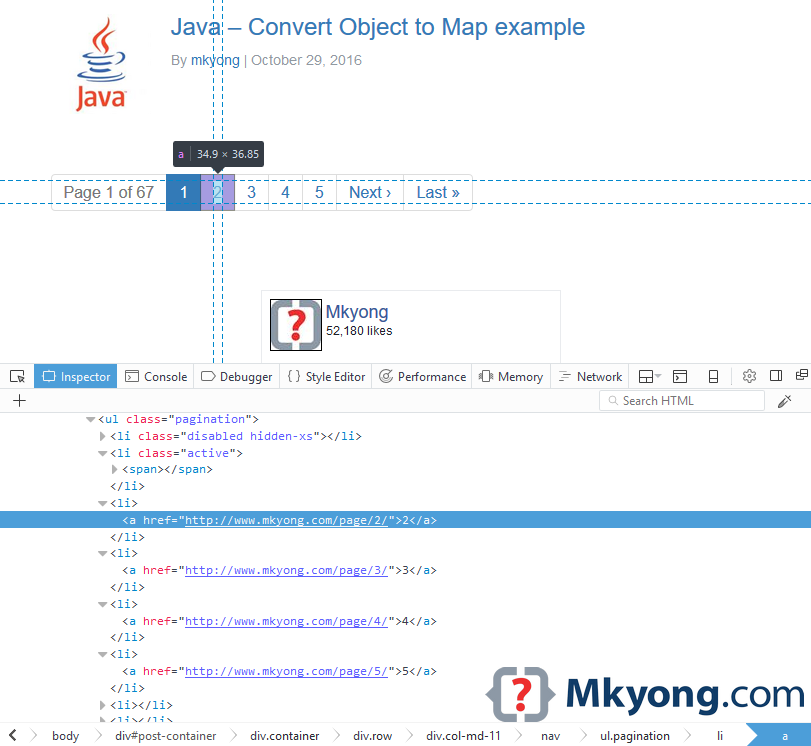
That brings us to the realization that the information we are looking for is easily accessed by retrieving all the links that include /page/. So instead of running through the whole website, we will limit our search using document.select("a[href^=\"https://mkyong.com/page/\"]"). With this css selector we collect only the links that start with https://mkyong.com/page/.
5.2 Next thing we notice is that the titles of the articles -which is what we want- are wrapped in <h2></h2> and <a href=""></a> tags.
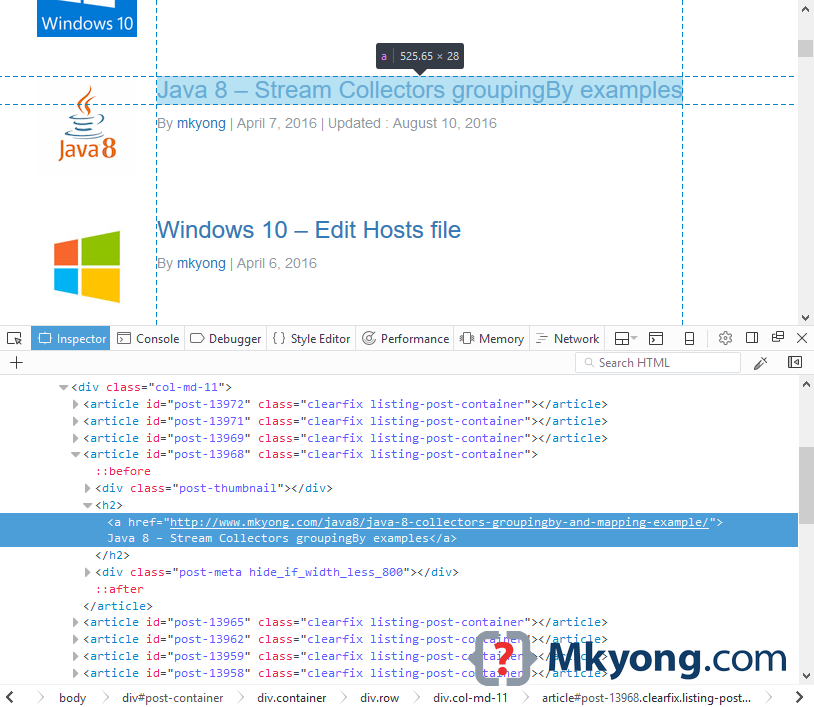
So to extract the article titles we will access that specific information using a css selector that restricts our select method to that exact information: document.select("h2 a[href^=\"https://mkyong.com/\"]");
5.3 Finally, we will only keep the links in which the title contains ‘Java 8’ and save them to a file.
package com.mkyong.extractor;
package com.mkyong;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
public class Extractor {
private HashSet<String> links;
private List<List<String>> articles;
public Extractor() {
links = new HashSet<>();
articles = new ArrayList<>();
}
//Find all URLs that start with "https://mkyong.com/page/" and add them to the HashSet
public void getPageLinks(String URL) {
if (!links.contains(URL)) {
try {
Document document = Jsoup.connect(URL).get();
Elements otherLinks = document.select("a[href^=\"https://mkyong.com/page/\"]");
for (Element page : otherLinks) {
if (links.add(URL)) {
//Remove the comment from the line below if you want to see it running on your editor
System.out.println(URL);
}
getPageLinks(page.attr("abs:href"));
}
} catch (IOException e) {
System.err.println(e.getMessage());
}
}
}
//Connect to each link saved in the article and find all the articles in the page
public void getArticles() {
links.forEach(x -> {
Document document;
try {
document = Jsoup.connect(x).get();
Elements articleLinks = document.select("h2 a[href^=\"https://mkyong.com/\"]");
for (Element article : articleLinks) {
//Only retrieve the titles of the articles that contain Java 8
if (article.text().matches("^.*?(Java 8|java 8|JAVA 8).*$")) {
//Remove the comment from the line below if you want to see it running on your editor,
//or wait for the File at the end of the execution
//System.out.println(article.attr("abs:href"));
ArrayList<String> temporary = new ArrayList<>();
temporary.add(article.text()); //The title of the article
temporary.add(article.attr("abs:href")); //The URL of the article
articles.add(temporary);
}
}
} catch (IOException e) {
System.err.println(e.getMessage());
}
});
}
public void writeToFile(String filename) {
FileWriter writer;
try {
writer = new FileWriter(filename);
articles.forEach(a -> {
try {
String temp = "- Title: " + a.get(0) + " (link: " + a.get(1) + ")\n";
//display to console
System.out.println(temp);
//save to file
writer.write(temp);
} catch (IOException e) {
System.err.println(e.getMessage());
}
});
writer.close();
} catch (IOException e) {
System.err.println(e.getMessage());
}
}
public static void main(String[] args) {
Extractor bwc = new Extractor();
bwc.getPageLinks("https://mkyong.com");
bwc.getArticles();
bwc.writeToFile("Java 8 Articles");
}
}
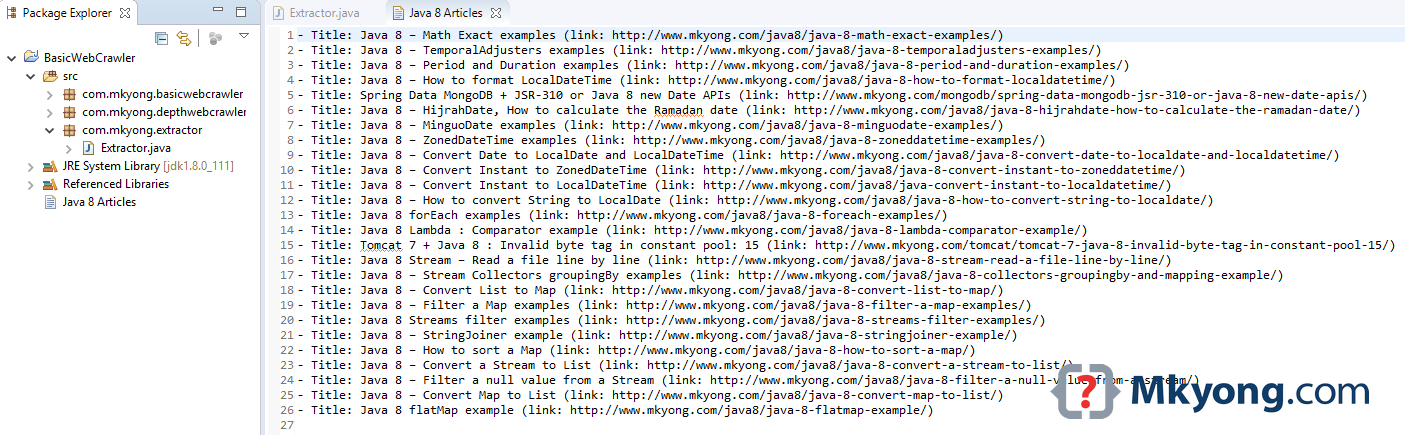
Output:
Hello, what if i dont know the MAX DEPTH of the website?
I am getting java.net.SocketException: Connection reset error when crawling https website
Can you make another example of this, but multithreaded?
I get “connect timed out” errors for many, but not all of the URLs, which this program attempts to connect to using this code.
Any idea why?
Thanks in advance!
Hello,
Really nice article, it helped us to get starting.
Is there any way to scrape dynamic website. A website which decides through javascript code about what cotent needs to be displayed and do not use href kind of structure for navigation?
thanks
-Prateek
I am using jdk 7 and jsoup 1.11.3
Really Helpful and well explained. 🙂
Thank you very much for all help Marilena !
for Document document = Jsoup.connect(URL)..get(); I cannot get the full HTML elements.
Even I do something like below I still cannot get the full elements. any idea on this?
Document document = Jsoup.connect(URL).header(“Accept-Encoding”, “gzip, deflate”)
.userAgent(“Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36”)
.maxBodySize(0)
.timeout(600000)
.get();